



Amazon and Universal Music Group Expand Partnership to Address ‘Unlawful AI-Generated Content’
![]()
Amazon and Universal Music Group (UMG) announced the expansion of their partnership on Monday. Among other topics, the two entities highlighted that the collaboration will focus on the advancement of artist-centric principles including increased fraud protection. While both the companies had a collaborative agreement in place, the new partnership expands its scope and includes product innovation, exclusive content rights with UMG artists, as well as a hollistic policy to address the issue of unlawful artificial intelligence (AI) content in the music industry.
Amazon and UMG to Tackle AI Issues in Music Industry
In a press release, UMG announced an expanded collaboration with Amazon that addresses several issues in the music industry, including AI-generated content which mimics the voice and likeness of an artist. In a joint statement, the companies highlighted a “shared commitment” to advance and safeguard human artistry.
“UMG and Amazon will also work collaboratively to address, among other things, unlawful AI-generated content, as well as protecting against fraud and misattribution,” the statement added.
Deepfakes or AI-generated music that resemble the voice and mannerisms of artists is a growing problem in the music industry. Last year, an AI-generated song called Heart on My Sleeve featuring the voices of Drake and The Weeknd was released on Spotify, Apple Music, and other music streaming platforms. The song quickly rose through the charts as listeners and platform believed it to be an authentic song. However, it was removed from the platforms after it was known to be created using AI.
This is one of many such examples where bad actors have used AI tools to generate music in the likeness of popular artists to generate revenue. Since AI-generated music is a legally grey area, authorities have not been able to take strong measures to protect artists so far.
In the announcement, UMG and Amazon acknowledged the disruption of AI-generated content and have stated the desire to collaborate to develop innovative products to identify and flag synthetic content on Amazon's platform.
Notably, earlier this year, Meta signed
a similar expansion of agreement to address unauthorised AI-generated
content to protect human artists and songwriters. The announcement,
however, did not reveal further details on the steps the companies plan
to take to minimise the risk of music deepfakes.

Tetsuwan Scientific Is Building AI-Powered Robotic Scientists That Can Carry Out Experiments
Tetsuwan Scientific, a San Francisco-based startup, is building artificial intelligence (AI) robotics that can perform the tasks of a scientist. The co-founders, CEO Cristian Ponce and the Chief Technology Officer (CTO) Théo Schäfer, brought the startup out of stealth in November after a successful seed round funding. The company aims to build intelligent software that can be integrated with lab robotics to automate the entire process of scientific discovery and invention, right from creating a hypothesis to running experiments, and drawing conclusions.
Building AI-Powered Robotics Scientists
Founded in 2023, the startup was working in stealth for the last year-and-a-half to build its first product — an AI scientist that can run experiments. It is now out of stealth and is currently working with La Jolla Labs in RNA therapeutic drug development. On its website, the startup has detailed its vision and the first product it is working on. Notably, it does not have any products in the public domain yet.
Highlighting the problem statement it aims to solve, the startup says that automation in science is focused on high volume of experiments instead of a high variety. This is because lab robots currently require extensive programming to replicate specific protocols. However, this has led to creation of a system that creates assembly lines instead of robots that can be assistant to scientists, the company said.
Tetsuwan Scientific stated that the problem is that robots cannot understand the scientific intent, and thus, cannot carry out an experiment on its own. However, looking at generative AI models, the company says, it is now possible to bridge this communication gap and teach robots how to act like a scientist. It is a two-pronged problem that requires an intelligent software combined with a versatile robotics hardware.
In an interview with TechCrunch, Ponce highlighted that large language models (LLMs) can bridge the software gap by allowing developers to communicate scientific intent to a robot without the requirement of writing thousands of lines of code. The CEO highlighted that the Retrieval-Augmented Generation (RAG) framework can also help in keeping AI hallucination down.
As per the publication, Tetsuwan Scientific is building non-humanoid robots. These robots, also showcased on the website, are large square shaped glass-like structure that are said to evaluate results and make changes to scientific experiments without requiring human intervention. These robots are said to be powered by AI software and sensors to gain knowledge about technical standards such as calibration, liquid class characterisation, and other properties.
Notably, the startup is currently in the initial stages towards its ultimate goal of building independent robotic AI scientists that can automate the entire scientific process and invent things.

Flamanville 3 Nuclear Reactor Begins Operations After Long Delays in France
France's nuclear energy sector reached a significant milestone as the Flamanville 3 European Pressurised Reactor in Normandy was successfully connected to the national electricity grid. According to reports, this reactor, now the country's most powerful with a capacity of 1,600 MW, began supplying electricity at 11:48 am local time on Saturday. Officials from EDF, the state-owned energy firm, highlighted to the media that the connection marks an important chapter in the nation's energy strategy, despite facing years of technical issues, delays, and cost overruns.
Decades in the Making
The Flamanville 3 project, initiated in 2007, was designed to revive interest in nuclear energy across Europe following past disasters. Reports have indicated that its advanced pressurised water reactor technology offers increased efficiency and improved safety measures. EDF's CEO, Luc Rémont, called the development “historic,” noting that it was the first new reactor to begin operations in France in 25 years. Challenges during the reactor's construction phase extended its timeline to 17 years, with costs escalating from an initial €3.3 billion to an estimated €13.2 billion.
Testing Phase and Future Plans
As per reports, it has been confirmed by EDF that Flamanville 3 will undergo extensive testing at varying power levels until summer 2025. A full inspection, lasting approximately 250 days, is expected to occur in spring 2026. The facility is projected to supply power to over two million homes once fully operational. France's nuclear programme remains one of the most prominent globally, contributing to about 60 percent of the nation's electricity output.
Government's Commitment to Nuclear Energy
President Emmanuel Macron has underscored the importance of nuclear energy in the country's shift towards sustainable power sources in the media. The government has announced plans for six additional next-generation reactors and possible options for eight more, reflecting its commitment to reducing dependence on fossil fuels. Macron previously described nuclear development as essential to safeguarding both energy security and the climate.

Samsung Galaxy M16 5G Leaked Renders Show Expected Design, Colour Options
Samsung Galaxy M16 5G may soon launch as a successor to the Galaxy M15 5G, which was unveiled in India in April. The purported handset has previously been spotted on multiple benchmarking and certification websites. These listings have suggested some expected key features of the phone. A recent report has shared leaked design renders of the anticipated smartphone, which shows its probable design and colour options. The Galaxy M16 5G from Samsung is expected to come with features similar to the ones seen on the Galaxy A16 5G, which was introduced in the country in October.
Samsung Galaxy M16 5G Design, Colour Options (Expected)
An Android Headlines report has shared leaked design renders of the Samsung Galaxy M16 5G. The phone appears with sharper borders on the flat sides, in contrast to the rounded edges of the preceding Galaxy M15 5G. This is closer to the design of many mid-range and flagship Samsung handsets. The phone appears in black, green and peach colour options.
The design of the rear camera module appears to be different from the existing Samsung Galaxy M15 5G as well. The purported Galaxy M16 5G is seen with a vertically placed pill-shaped camera island that holds three sensors. Within the module, a larger slot holds two sensors, while a smaller, circular slot has a third. An LED flash unit is placed outside the rear camera module on the top left corner of the panel.
The left edge of the Samsung Galaxy M16 5G holds the SIM card slot, while the right edge has the volume rockers and the power button, that doubles as a fingerprint sensor. The handset is tipped to get an AMOLED screen with slim bezels, a relatively thicker chin and an Infinity-U notch at the top to house the front camera sensor.
Previously, the Samsung Galaxy M16 5G with the model number SM-M166P/DS was spotted on the Bureau of Indian Standards (BIS) website, suggesting an imminent India launch. A Wi-Fi Alliance listing suggested the phone would likely support 2.4GHz and 5GHz dual-band Wi-Fi and ship with Android 14-based One UI 6. A Geekbench listing suggested the handset could get a MediaTek Dimensity 6300 SoC with support for 8GB of RAM.
![]()

MIT Researchers Measure Quantum Geometry of Electrons in Solid Materials for First Time
A new study has allowed physicists from the Massachusetts Institute of Technology (MIT) and collaborators to measure the quantum geometry of electrons in solids. The research provides insights into the shape and behaviour of electrons within crystalline materials at a quantum level. Quantum geometry, which had previously been limited to theoretical predictions, has now been directly observed, enabling unprecedented avenues for manipulating quantum material properties, according to the study. New Pathways for Quantum Material Research The study was published in Nature Physics on November 25. As described by Riccardo Comin, Class of 1947 Career Development Associate Professor of Physics at MIT, the achievement is a major advancement in quantum material science. In an interview with MIT's Materials Research Laboratory, Comin highlighted that their team has developed a blueprint for obtaining completely new information about quantum systems. The methodology used can potentially be applied to a wide range of quantum materials beyond the one tested in this study. Technical Innovations Enable Direct Measurement The research employed angle-resolved photoemission spectroscopy (ARPES), a technique previously used by Comin and his colleagues to examine quantum properties. The team adapted ARPES to directly measure quantum geometry in a material known as kagome metal, which features a lattice structure with unique electronic properties. Mingu Kang, first author of the paper and a Kavli Postdoctoral Fellow at Cornell University, noted that this measurement became possible due to collaboration between experimentalists and theorists from multiple institutions, including South Korea during the pandemic.
These experiences underscore the collaborative and resourceful efforts involved in realising this scientific breakthrough. This advancement offers new possibilities in understanding the quantum behaviour of materials, paving the way for innovations in computing, electronics, and magnetic technologies, as reported in Nature Physics.

Nvidia’s new AI audio model can synthesize sounds that have never existed
At this point, anyone who has been following AI research is long familiar with generative models that can synthesize speech or melodic music from nothing but text prompting. Nvidia's newly revealed "Fugatto" model looks to go a step further, using new synthetic training methods and inference-level combination techniques to "transform any mix of music, voices, and sounds," including the synthesis of sounds that have never existed.
While Fugatto isn't available for public testing yet, a sample-filled website showcases how Fugatto can be used to dial a number of distinct audio traits and descriptions up or down, resulting in everything from the sound of saxophones barking to people speaking underwater to ambulance sirens singing in a kind of choir. While the results on display can be a bit hit or miss, the vast array of capabilities on display here helps support Nvidia's description of Fugatto as "a Swiss Army knife for sound."
You’re only as good as your data
In an explanatory research paper, over a dozen Nvidia researchers explain the difficulty in crafting a training dataset that can "reveal meaningful relationships between audio and language." While standard language models can often infer how to handle various instructions from the text-based data itself, it can be hard to generalize descriptions and traits from audio without more explicit guidance.
To that end, the researchers start by using an LLM to generate a Python script that can create a large number of template-based and free-form instructions describing different audio "personas" (e.g., "standard, young-crowd, thirty-somethings, professional"). They then generate a set of both absolute (e.g., "synthesize a happy voice") and relative (e.g., "increase the happiness of this voice") instructions that can be applied to those personas.
The wide array of open source audio datasets used as the basis for Fugatto generally don't have these kinds of trait measurements embedded in them by default. But the researchers make use of existing audio understanding models to create "synthetic captions" for their training clips based on their prompts, creating natural language descriptions that can automatically quantify traits such as gender, emotion, and speech quality. Audio processing tools are also used to describe and quantify training clips on a more acoustic level (e.g. "fundamental frequency variance" or "reverb").
To that end, the researchers start by using an LLM to generate a Python script that can create a large number of template-based and free-form instructions describing different audio "personas" (e.g., "standard, young-crowd, thirty-somethings, professional"). They then generate a set of both absolute (e.g., "synthesize a happy voice") and relative (e.g., "increase the happiness of this voice") instructions that can be applied to those personas.
The wide array of open source audio datasets used as the basis for Fugatto generally don't have these kinds of trait measurements embedded in them by default. But the researchers make use of existing audio understanding models to create "synthetic captions" for their training clips based on their prompts, creating natural language descriptions that can automatically quantify traits such as gender, emotion, and speech quality. Audio processing tools are also used to describe and quantify training clips on a more acoustic level (e.g. "fundamental frequency variance" or "reverb").
For relational comparisons, the researchers rely on datasets where one factor is held constant while another changes, such as different emotional readings of the same text or different instruments playing the same notes. By comparing these samples across a large enough set of data samples, the model can start to learn what kinds of audio characteristics tend to appear in "happier" speech, for instance, or differentiate the sound of a saxophone and a flute.
After running a variety of different open source audio collections through this process, the researchers ended up with a heavily annotated dataset of 20 million separate samples representing at least 50,000 hours of audio. From there, a set of 32 Nvidia tensor cores was used to create a model with 2.5 billion parameters that started to show reliable scores on a variety of audio quality tests.
It’s all in the mix
 OK, Fugatto, can we get a little more barking and a little less saxophone in the monitors?
Credit:
Getty Images
OK, Fugatto, can we get a little more barking and a little less saxophone in the monitors?
Credit:
Getty Images
Beyond the training, Nvidia is also talking up Fugatto's "ComposableART" system (for "Audio Representation Transformation"). When provided with a prompt in text and/or audio, this system can use "conditional guidance" to "independently control and generate (unseen) combinations of instructions and tasks" and generate "highly customizable audio outputs outside the training distribution." In other words, it can combine different traits from its training set to create entirely new sounds that have never been heard before.
I won't pretend to understand all of the complex math described in the paper—which involves a "weighted combination of vector fields between instructions, frame indices and models." But the end results, as shown in examples on the project's webpage and in an Nvidia trailer, highlight how ComposableART can be used to create the sound of, say, a violin that "sounds like a laughing baby or a banjo that's playing in front of gentle rainfall" or "factory machinery that screams in metallic agony." While some of these examples are more convincing to our ears than others, the fact that Fugatto can take a decent stab at these kinds of combinations at all is a testament to the way the model characterizes and mixes extremely disparate audio data from multiple different open source data sets.
Perhaps the most interesting part of Fugatto is the way it treats each individual audio trait as a tunable continuum, rather than a binary. For an example that melds the sound of an acoustic guitar and running water, for instance, the result ends up very different when either the guitar or the water is weighted more heavily in Fugatto's interpolated mix. Nvidia also mentions examples of tuning a French accent to be heavier or lighter, or varying the "degree of sorrow" inherent in a spoken clip.
Beyond tuning and combining different audio traits, Fugatto can also
perform the kinds of audio tasks we've seen in previous models, like
changing the emotion in a piece of spoken text or isolating the vocal
track in a piece of music. Fugatto can also detect individual notes in a
piece of MIDI music and replace them with a variety of vocal
performances, or detect the beat of a piece of music and add effects
from drums to barking dogs to ticking clocks in a way that matches the
rhythm.
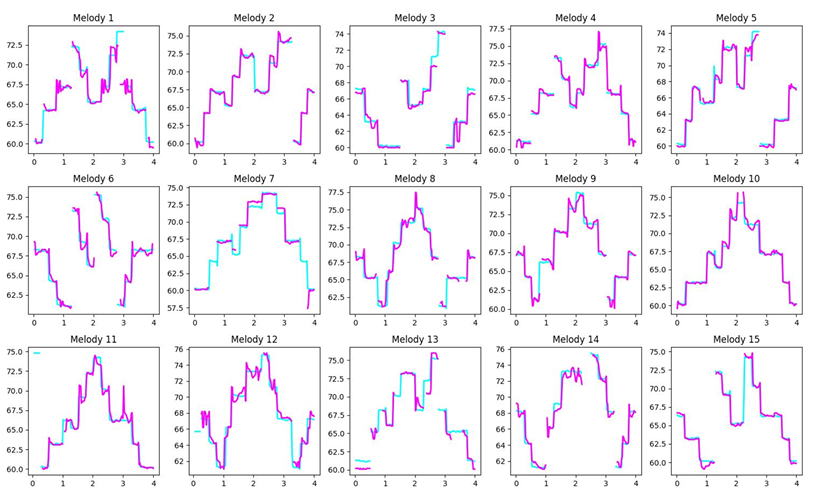

Nvidia Reveals ‘Swiss Army Knife’ of AI Audio Tools: Fugatto
High-powered computer chip maker Nvidia on Monday unveiled a new AI model developed by its researchers that can generate or transform any mix of music, voices and sounds described with prompts using any combination of text and audio files.
The new AI model called Fugatto — for Foundational Generative Audio Transformer Opus — can create a music snippet based on a text prompt, remove or add instruments from an existing song, change the accent or emotion in a voice, and even produce sounds never heard before.
According to Nvidia, by supporting numerous audio generation and transformation tasks, Fugatto is the first foundational generative AI model that showcases emergent properties — capabilities that arise from the interaction of its various trained abilities — and the ability to combine free-form instructions.
“We wanted to create a model that understands and generates sound like humans do,” Rafael Valle, a manager of applied audio research at Nvidia, said in a statement.
“Fugatto is our first step toward a future where unsupervised multitask learning in audio synthesis and transformation emerges from data and model scale,” he added.
Nvidia noted the model is capable of handling tasks it was not pretrained on, as well as generating sounds that change over time, such as the Doppler effect of thunder as a rainstorm passes through an area.
The company added that unlike most models, which can only recreate the training data they’ve been exposed to, Fugatto allows users to create soundscapes it’s never seen before, such as a thunderstorm easing into dawn with the sound of birds singing.
Breakthrough AI Model for Audio Transformation
“Nvidia’s introduction of Fugatto marks a significant advancement in AI-driven audio technology,” observed Kaveh Vahdat, founder and president of RiseOpp, a national CMO services company based in San Francisco.
“Unlike existing models that specialize in specific tasks — such as music composition, voice synthesis, or sound effect generation — Fugatto offers a unified framework capable of handling a diverse array of audio-related functions,” he told TechNewsWorld. “This versatility positions it as a comprehensive tool for audio synthesis and transformation.”
Vahdat explained that Fugatto distinguishes itself through its ability to generate and transform audio based on both text instructions and optional audio inputs. “This dual-input approach enables users to create complex audio outputs that seamlessly blend various elements, such as combining a saxophone’s melody with the timbre of a meowing cat,” he said.
Additionally, he continued, Fugatto’s capacity to interpolate between instructions allows for nuanced control over attributes like accent and emotion in voice synthesis, offering a level of customization not commonly found in current AI audio tools.
“Fugatto is an extraordinary step towards AI that can handle multiple modalities simultaneously,” added Benjamin Lee, a professor of engineering at the University of Pennsylvania.
“Using both text and audio inputs together may produce far more efficient or effective models than using text alone,” he told TechNewsWorld. “The technology is interesting because, looking beyond text alone, it broadens the volumes of training data and the capabilities of generative AI models.”
“The voice isolation was clumsy and unmusical,” he told TechNewsWorld. “The additional instruments were also trivial, and most of the transformations were colorless. The only advantage is that it requires no particular learning, so the development of musicality for the AI user will be minimal.”
“It may usher in some new uses — real musicians are wonderfully inventive already — but unless the developers have better musical chops to begin with, the results will be dreary,” he said. “They will be musical slop to join the visual and verbal slop from AI.”
AGI Stand-In
With artificial general intelligence (AGI) still very much in the future, Fugatto may be a model for simulating AGI, which ultimately aims to replicate or surpass human cognitive abilities across a wide range of tasks.
“Fugatto is part of a solution that uses generative AI in a collaborative bundle with other AI tools to create an AGI-like solution,” explained Rob Enderle, president and principal analyst at the Enderle Group, an advisory services firm in Bend, Ore.
“Until we get AGI working,” he told TechNewsWorld, “this approach will be the dominant way to create more complete AI projects with far higher quality and interest.”
Nvidia at Its Best
Mark N. Vena, president and principal analyst at SmartTech Research in Las Vegas, asserted that Fugatto represents Nvidia at its best.
“The technology introduces advanced capabilities in AI audio processing by enabling the transformation of existing audio into entirely new forms,” he told TechNewsWorld. “This includes converting a piano melody into a human vocal line or altering the accent and emotional tone of spoken words, offering unprecedented flexibility in audio manipulation.”
“Unlike existing AI audio tools, Fugatto can generate novel sounds from text descriptions, such as making a trumpet sound like a barking dog,” he said. “These features provide creators in music, film, and gaming with innovative tools for sound design and audio editing.”
Fugatto deals with audio holistically — spanning sound effects, music, voice, virtually any type of audio, including sounds that have not been heard before — and precisely, added Ross Rubin, the principal analyst with Reticle Research, a consumer technology advisory firm in New York City.
He cited the example of Suno, a service that uses AI to generate songs. “They just released a new version that has improvements in how generated human voices sound and other things, but it doesn’t allow the kinds of precise, creative changes that Fugatto allows, such as adding new instruments to a mix, changing moods from happy to sad, or moving a song from a minor key to a major key,” he told TechNewsWorld.
“Its understanding of the world of audio and the flexibility that it offers goes beyond the mask-specific engines that we’ve seen for things like generating a human voice or generating a song,” he said.
Opens Door for Creatives
Vahdat pointed out that Fugatto can be useful in both advertising and language learning. Agencies can create customized audio content that aligns with brand identities, including voiceovers with specific accents or emotional tones, he noted.
At the same time, in language learning, educational platforms will be able to develop personalized audio materials, such as dialogues in various accents or emotional contexts, to aid in language acquisition.
“Fugatto technology opens doors to a wide array of applications in creative industries,” Vena maintained. “Filmmakers and game developers can use it to create unique soundscapes, such as turning everyday sounds into fantastical or immersive effects,” he said. “It also holds potential for personalized audio experiences in virtual reality, assistive technologies, and education, tailoring sounds to specific emotional tones or user preferences.”
“In music production,” he added, “it can transform instruments or vocal styles to explore innovative compositions.”
Further development may be needed to get better musical results, however. “All these results are trivial, and some have been around for longer — and better,” observed Dennis Bathory-Kitsz, a musician and composer in Northfield Falls, Vt.
“The voice isolation was clumsy and unmusical,” he told TechNewsWorld. “The additional instruments were also trivial, and most of the transformations were colorless. The only advantage is that it requires no particular learning, so the development of musicality for the AI user will be minimal.”
“It may usher in some new uses — real musicians are wonderfully inventive already — but unless the developers have better musical chops to begin with, the results will be dreary,” he said. “They will be musical slop to join the visual and verbal slop from AI.”
AGI Stand-In
With artificial general intelligence (AGI) still very much in the future, Fugatto may be a model for simulating AGI, which ultimately aims to replicate or surpass human cognitive abilities across a wide range of tasks.
“Fugatto is part of a solution that uses generative AI in a collaborative bundle with other AI tools to create an AGI-like solution,” explained Rob Enderle, president and principal analyst at the Enderle Group, an advisory services firm in Bend, Ore.
“Until we get AGI working,” he told TechNewsWorld, “this approach will be the dominant way to create more complete AI projects with far higher quality and interest.”